mesh tensorflow 정리글
mesh tensorflow 정리글
요약
batch-spliting이란, data-paralleism 방법론으로 분산화된 딥러닝 네트워크에서 많이 사용하며, Single-Program-Multiple-Data programing의 일종이다. 즉, 데이터가 클 때 분산시켜서 대처하는 방법론이라고 할 수 있다.
하지만, 모델이 한번에 RAM에 올리기 클 경우에는 어떻게 해야할까? 혹은 모델의 크기 때문에 작은 batch size를 사용할 때 발생하는 high latency와 비효율성이 발생한다면 어떻게 해야할까? 이를 해결하기 위해서는 Model-parallenism을 사용해야한다.
하지만, 효과적인 model-parallelism은 일반적으로 복잡한 편이다. 이런 문제를 간단하게 해결하기 위해서 Mesh-tensorflow를 제안한다. data-parallelism은 tensor와 operations를 batch dimension으로 나누는 것으로 치환한다.
Data-paralleism
특징은 다음과 같다.
- 각 core마다 복사되는 Parameters
- core마다 분산되는 batch
- sum(allreduce) parameters gradients
장점은 다음과 같다.
- 보편적으로 사용되는 방식이다.
- Compile 시간이 빠르다. (SPMD)
- Full Utilization
- locally-connected network조건하에서 allreduce가 빠르게 적용된다.
단점은 다음과 같다.
- 모든 parameters가 하나의 core에 실을 수 있어야 한다.
Transformer LM - 5B Parameters
Data-parellesim을 Transformer와 같은 큰 모델에 적용할 경우 문제가 발생한다. 각 core마다 모델 파라미터를 저장해야하는데, 이는 out-of-memory문제를 야기하거나 batch size를 크게 사용하지 못하는 상황이 발생한다.
Model-paralleism
장점은 다음과 같다.
- 거대한 모델을 학습시킬 수 있다.
- potentially low latency
단점은 다음과 같다.
- 적용하기 힘들다.
Mesh-Tensorflow
Mesh-Tensorflow의 장점은 다음과 같다.
- Every processor involved in every operation.
- Single Program Multiple Devices(SPMD)
- collective communication (like allreduce)
Mesh-Tensorflow에서는 다음과 같은 역할을 하고자 한다.
- Data-parallelism (batch-spliting)
- Model-parallelism(model-spliting)
- Spatial Spliting of large inputs
- Combinations of these
적용되는 하드웨어는 아래와 같은 특징을 가진다.
- 유사한 프로세서로 구성되어 있으며
- n-dimensional mesh로 여길 수 있다
- like multi-gpu, multi-cpu
User defines which dimension is split
Data-parallelism같은 경우에는 batch dimentsion을 가지고 분리한다.
- batch dimension이 있는 경우: batch dimension으로 나눈다.
- batch dimension이 없는 경우: parameters를 복사한다.
Model-Paralleism같은 경우 위와 다른 dimension을 분리한다. 예를 들면, hidden layer size dimension이 있을 수 있다.
Where does communication happen?
대부분의 연산들은 같은 프로세서안에서의 input들의 조각을 계산한다. 하지만, allreduce처럼 다른 프로세서의 output에 대해서 연산을 해야할 때도 있다. 이 때 collective communication이 필요하다.
Case Study
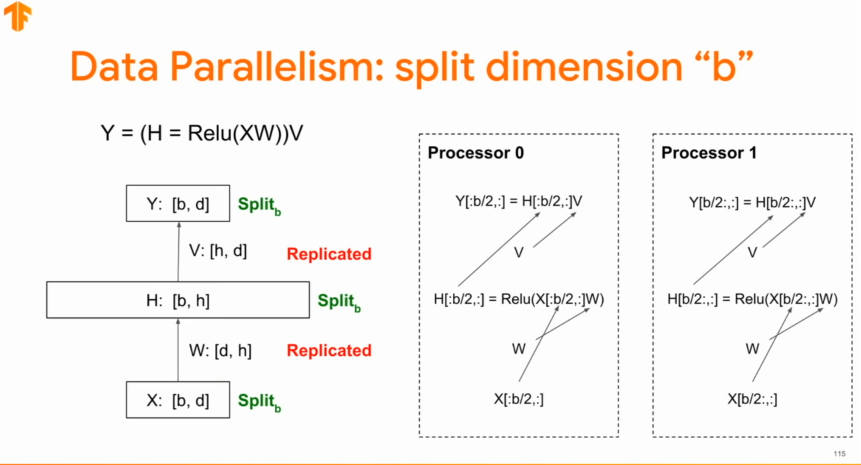
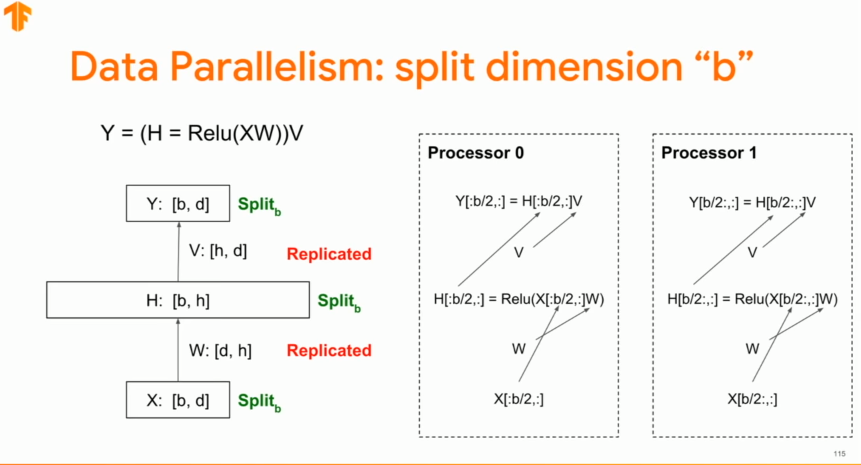
위의 이미지는 간단한 뉴럴네트워크를 batch dimension기준으로 분리한 것이다. - data parreliesm
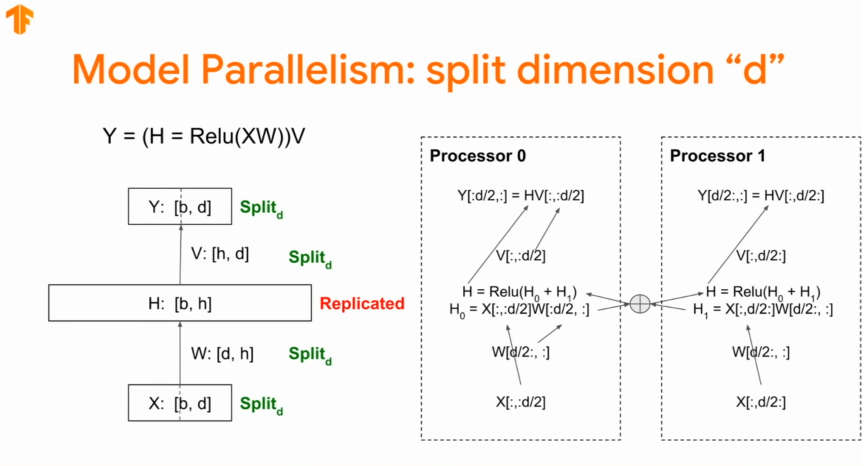
위의 이미지는 hidden layer dimension을 기준으로 분리한 것이다.
 위의 이미지는 data dimension을 기준으로 분리한 것이다.
위의 이미지는 data dimension을 기준으로 분리한 것이다.
아래의 이미지는 data-parallelism과 Model parallelism을 함께 구성한 것이다.

Layout for Transformer Model
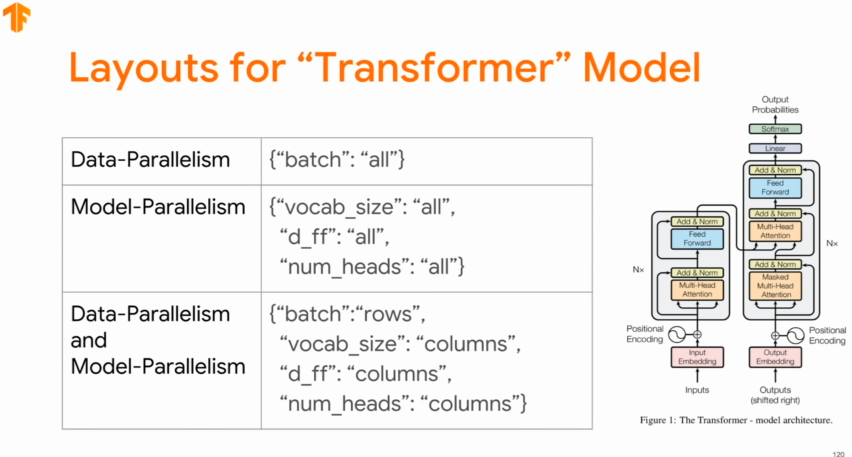
Picking a Good Layout
- 반복되는 업무를 피하기 위해서, 연산량이 많은 matmul/einsum은 모든 mesh dimension에 따라서 분리되어야 한다.
- 같은 tensor에서 두가지 종류의 dimension으로 분리할 수 없다
- 너무 잘게 나누면 communication 비용이 올라가므로 유의해야한다.
Example
- Describing the mathematical operations
# tf_images is a tf.Tensor with shape [100, 28, 28] and dtype tf.float32
# tf_labels is a tf.Tensor with shape [100] and dtype tf.int32
import mesh_tensorflow as mtf
graph = mtf.Graph()
mesh = mtf.Mesh(graph, "my_mesh")
batch_dim = mtf.Dimension("batch", 100)
rows_dim = mtf.Dimension("rows", 28)
cols_dim = mtf.Dimension("cols", 28)
hidden_dim = mtf.Dimension("hidden", 1024)
classes_dim = mtf.Dimension("classes", 10)
images = mtf.import_tf_tensor(
mesh, tf_images, shape=[batch_dim, rows_dim, cols_dim])
labels = mtf.import_tf_tensor(mesh, tf_labels, [batch_dim])
w1 = mtf.get_variable(mesh, "w1", [rows_dim, cols_dim, hidden_dim])
w2 = mtf.get_variable(mesh, "w2", [hidden_dim, classes_dim])
# einsum is a generalization of matrix multiplication (see numpy.einsum)
hidden = mtf.relu(mtf.einsum(images, w1, output_shape=[batch_dim, hidden_dim]))
logits = mtf.einsum(hidden, w2, output_shape=[batch_dim, classes_dim])
loss = mtf.reduce_mean(mtf.layers.softmax_cross_entropy_with_logits(
logits, mtf.one_hot(labels, classes_dim), classes_dim))
w1_grad, w2_grad = mtf.gradients([loss], [w1, w2])
update_w1_op = mtf.assign(w1, w1 - w1_grad * 0.001)
update_w2_op = mtf.assign(w2, w2 - w2_grad * 0.001)
- Describing tensor/computation layout: data-parallelism
devices = ["gpu:0", "gpu:1", "gpu:2", "gpu:3"]
mesh_shape = [("all_processors", 4)]
layout_rules = [("batch", "all_processors")] # batch dimension을 각 gpu의 개수만큼 분산
mesh_impl = mtf.placement_mesh_impl.PlacementMeshImpl(
mesh_shape, layout_rules, devices)
lowering = mtf.Lowering(graph, {mesh:mesh_impl})
tf_update_ops = [lowering.lowered_operation(update_w1_op),
lowering.lowered_operation(update_w2_op)]
- Alternatively model-parallelism
devices = ["gpu:0", "gpu:1", "gpu:2", "gpu:3"]
mesh_shape = [("processor_rows", 2), ("processor_cols", 2)] # modified
layout_rules = [("batch", "processor_rows"), ("hidden", "processor_cols")] # modified, row * col 사각형 형태의 mesh 형성
mesh_impl = mtf.placement_mesh_impl.PlacementMeshImpl(
mesh_shape, layout_rules, devices)
lowering = mtf.Lowering(graph, {mesh:mesh_impl})
tf_update_ops = [lowering.lowered_operation(update_w1_op),
lowering.lowered_operation(update_w2_op)]
Reference
- https://www.youtube.com/watch?v=HgGyWS40g-g
- https://github.com/tensorflow/mesh
- https://arxiv.org/abs/1811.02084