Faster-RCNN 정리글
Faster-RCNN 정리글
Problem: bottleneck
기존의 state-of-the-art object detection network는 region proposal algorithm을 사용하였다. (ex-Fast R-CNN) region proposal algorithm은 이들 network상에서 bottleneck의 역할을 하고 있었다. 즉, region proposal algorithm 때문에 학습 시간 및 알고리즘 수행시간이 지체되고 있는 것을 확인했다.
이러한 문제를 해결하기 위해서 Region Proposal Network를 제안하는데 이는 full-image convolutional feature를 region proposal하는데도 사용하여 cost-free하게 적용될 수 있다.
[비교] Fast-RCNN: region proposal algorithm
한 이미지 당 cpu기준 약 2초의 시간이 걸린다.

- reference: https://donghwa-kim.github.io/SelectiveSearch.html
Faster-RCNN

Faster-RCNN은 두 가지 모듈로 구성된다.
- Deep fully convolutional network that proposes regions
- Fast R-CNN detector(classfier): 1에서 추출된 regioin을 사용한다.
중요한 점은 1, 2가 진행되는 동안 feature를 공유한다는 것이다. (cost-free)
Region Proposal Networks
어떤 사이즈의 이미지가 들어와도 직사각형의 object proposal을 output으로 가진다.

이 논문의 목표는 detector의 computation과 proposal의 computation을 공유하는 것이기 때문에 위와 같은 convolution layers를 공유한다고 가정하였다.
- ZF: 5 sharable convolutional layers
- VGG-16: 13 sharable convolutional layers
이렇게 공유된 feature들은 두 가지 용도로 사용하게 된다. ($n \times n$의 spatial window를 사용하여 얻은 feature)
- box regression: proposal
- box classification: detector
해당 논문에서는 $n = 3$으로 feature를 생성했는데, 이는 일반적인 reception field로는 작은 숫자이다. 이렇게 작게 설정한 이유는 sliding window가 모든 spatial location을 탐색할 수 있게끔 설계한 것이다.
Anchors
sliding window의 위치가 변할 때 마다, multiple region proposals이 이루어진다.
한 위치에서 나올수 있는 region proposal의 최대 개수를 $k$라고 한다면,
-
regression box: $4k$의 outputs, $k$박스의 각 좌표(꼭지점)
-
classfier: $2k$의 outputs, object or not
-
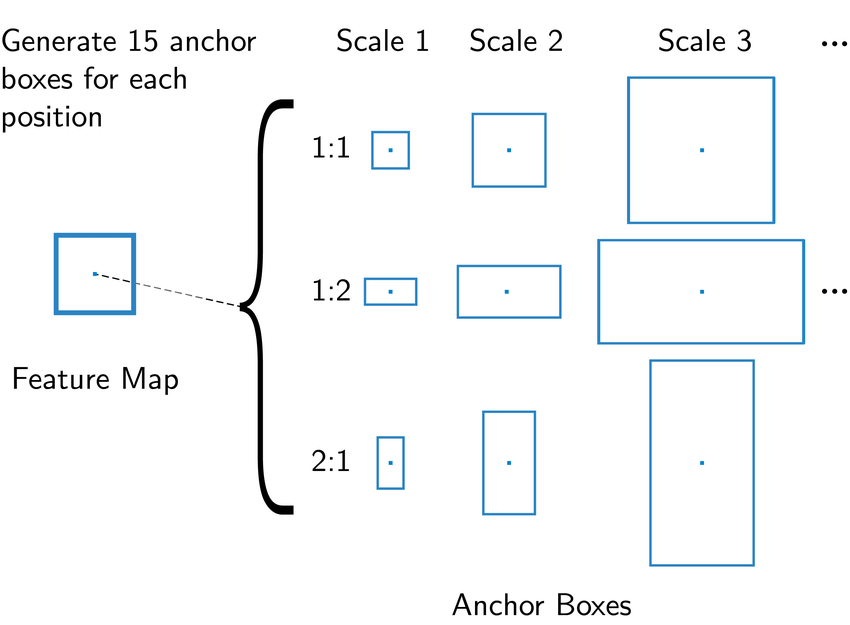
위의 그림은 anchor의 scale과 ratio에 변화이다. 해당 논문에서는 위의 그림과 같이 9 종류의 anchor를 사용하였다. 따라서 해당 이미지의 크기가 $W \times H$라면 $W \times H \times k$개의 anchor가 존재한다.
Translation-Invariant Anchors
translation-invariant의 특성이란

물체가 특정 위치에 존재할 때만 탐지되거나 혹은 특정 위치에서는 탐지가 잘 안되는 현상을 줄이는 것
- reference: https://medipixel.github.io/post/anchor-target/?fbclid=IwAR3sCN1gXjcpt0SNcBgCpVsW8Y6jo2u-2MrBkrQGQgy3CSIKkUPPHGt4YY8
이를 확인하기 위해서 MultiBox method와 비교하게 되는데, 이는 k-means 방법론을 사용하며 800개의 anchor를 생성한다. 하지만 이는 translation invariant가 아니다.
translation invariant의 특성은 model size를 작게 사용할 수 있게 해준다. MultiBox의 경우 $(4 + 1) * 800$-dimensional fully-connected network를 사용하는 반면에, Faster-RCNN은 $(4 + 2) * 9$-dimensional convolutional output layer만 있으면 가능하다. 즉, $512 * (4 + 2) * 9 \approx 2.8 * 10^4$의 파라미터만으로 해결 할 수 있다. (box: 4, cls: 2) 반면에, MultiBox는 약 $ 1536 * (4 + 1) * 800 \approx 6.1 * 10^6 $의 파라미터가 필요하다. 따라서, overfitting 문제에 있어서 Faster-RCNN이 더 우수할 것으로 기대된다. ($1536=512 * 3$)
Multi-Scale Anchors as Regression References
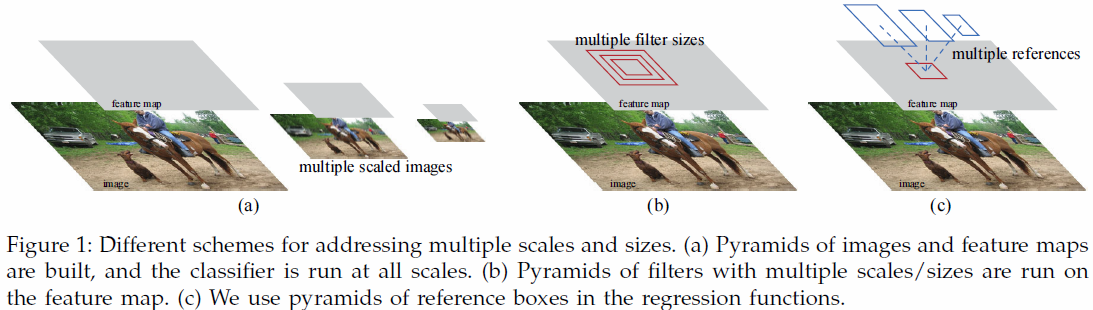
multi-scale prediction에는 두 가지 방법이 있다. 그리고 이 두가지 방법은 종종 혼합하여 사용된다. 해당 논문에서는 cost-efficient한 두 번째 방법을 사용하였다.
- image/feature pyramids -Figure 1 (a)
- 이미지를 다양한 크기로 resize한 후 feature map은 각 resize된 이미지에서 뽑아낸다.
- 효과적이긴 하나, computation 시간이 오래 걸린다.
- multiple scale sliding window
- 다양한 크기의 window를 sliding하여 feature을 얻는다.
- pyramid of filters
- image/feature pyramids을 사용하지 않게 하기 때문에 scale을 다루는데 추가적인 cost가 발생하지 않는다.(rescale and feature)
Loss Function
RPN을 학습할 때는 각 anchor에 대해서 binary class label로 학습이 진행된다. (object or not) positive label이 부여되는 경우는 두 가지이다.
- anchor/ anchors with the highest IOU score with ground-truth boxes
- union anchor: ground-truth box와의 IOU 점수가 0.7이상인 경우
보통은 2번째 조건으로만 postive sample을 만들 수 있지만, 희귀한 경우에 2번째 조건만으로 찾지 못하는 경우가 있다. 그래서 1번째 조건도 추가한다.
negative label의 경우 IOU점수가 0.3보다 낮은 anchor에 부여된다.(ground-truth) positive 혹은 negative에 속하지 못하는 anchor는 train objective에 영향을 주지 않는다.
아래는 objective이다.
- $i$는 anchor의 index를 의미한다.
- $p_i^*$는 ground-truth label을 의미하며 1이 postive이다.
- $t_i^*$는 4차원의 vector로 bounding box를 의미한다. (ground-truth)
- $p_i^L_{reg}(t_i, t_i^)$은 positive sample일때만 적용된다는 뜻이다.
Bounding box regression은 어떻게 적용되는가? $L_1$ loss가 적용되며 vector가 다음과 같이 변환된다.
- $x$: predicted box
- $x_a$: anchor box
- $x^*$: ground truth box
위의 방법은 기존에 사용되던 Region of Interest methods와 다르다. ROI method에서는 bounding-box regression이 arbitrarily sized ROI에서 뽑힌 feature를 바탕으로 진행되며, 모든 region size에 대해서 weight를 공유한다. 반면에 위의 방법론은 feature map의 spatial size가 3 * 3으로 고정되어 있으며 변하는 size에 다루기 위해서는 다양한 anchor를 사용한다. 이 때, 각 anchor끼리는 weight를 공유하지 않는다.
하지만, 위에서 언급했듯이 이전의 region proposal 방법론은 효율적이지 못하다는 단점이 있다.
Training RPNs
image-centric sampling 방법론을 사용한다.
각 mini-batch에서 image상에는 많은 positives와 negatives가 존재한다. 이를 그대로 학습시킨다면 일반적으로 negative sample의 수가 많기 때문에 편향될 위험이 있다. 따라서, positive sample과 negative sample을 random하게 1:1로 추출한다음 학습을 진행한다. (p: 128, n:128)
Sharing Features for RPN and Fast R-CNN
이제 detection network를 고려해보자. detection network와 regioin proposal network를 독립적으로 학습시킨다면 이는 서로 다른 방법으로 학습이 될 것으로 기대된다. 따라서 convolution layer를 공유하기 위해서는 새로운 방법이 필요하다.
-
Alternating training
먼저 RPN을 학습시킨다 다음, RPN에서 나오는 Proposal을 바탕으로 Fast-RCNN을 학습시킨다. 해당 논문에서는 이 방법론을 사용한다.
-
Apporximate joint training:
Fast-RCNN과 RPN을 하나의 network로 만든다. SGD interations동안 forward pass에서 region proposal을 생성하고 이는 Fast-RCNN detector를 학습시키는 동안 미리 계산되고 고정되어 있다.(not differential) backward pass에서는 RPN loss와 Fast_RCNN loss가 더해져서 total loss로 정의된다. 이는 쉽게 적용될 수 있으나, 이는 proposal box에 대한 gradient값을 무시하게 된다. (approximate한다)
해당 실험에서는 학습시간을 줄이면서 결과는 유사하게 나오는 것을 확인할 수 있었다. (reduce 25% ~ 50% train time)
-
Non-approximate joint training
Apporximate joint training과 다르게 box coordinates에 대해서 미분가능하다.
bbox에 미분가능한 ROI pooling layer가 필요하다.
4-Step Alternating Training
- RPN 학습, (initialized with an ImageNet-pre-trained model )
- 1에서 학습학 RPN을 바탕으로 regioin proposal 생성 후 Fast-RCNN detector 학습(initialized with an ImageNet-pre-trained model) 이 step에서는 layer를 공유하지 않는다.
- detector network를 RPN initialization에 사용한다. 공유되는 layer는 고정시키고 RPN에만 적용되는 layer만 학습시킨다. 이 step에서 layer를 공유한다.
- 공유되는 layer는 고정시키고 Fast-RCNN에만 적용되는 layer를 학습시킨다.
Implementation Detatils
image/feature pyramids -Figure 1 (a)과 multi scale sliding window 두 가지 방법 모두 실험해보았다. 하지만 첫번째 방법론은 speed-accuracy trade-off가 좋지 않음을 확인할 수 있었다.
Recall to IOU
일반적으로 전반적인 detection accuracy와 관련있는 metric이다.
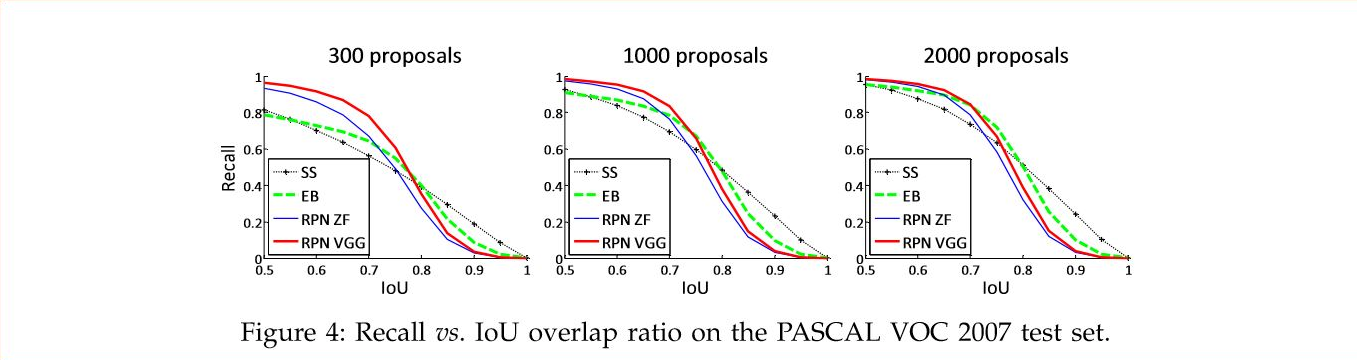
위의 이미지를 보면 알 수 있듯이, SS, EB가 더 빠르게 감소하는 recall을 확인할 수 있다.
recall이란
TP / total ground-truth