Feature Visulatization 번역글
Feature Visulatization 번역글
Introduction
neural network의 해석가능성에 대한 필요성이 늘어나고 있다. Deep learning의 해석가능성은 크게 두 가지 문제로 나뉜다.
-
feature visualization

network 혹은 network의 부분이 무엇을 보고자 하는가
-
attribution
network가 다음과 같이 동작하는 이유가 무엇인가
class activation map이 하나의 예시가 될 수 있다.
Feature Visualization by Optimization
일반적으로 neural network는 input에 대해서 differentiable하다. 만약 당신이 어떤 종류의 input이 특정한 행동양상을 가지는지 알고 싶다면(내부적인 뉴런의 동작 혹은 마지막 결과물의 양상이 예시가 될 수 있다.), iteratively 미분하면서 목표를 이룰수 있다. 이렇게 얘기하면 매우 쉬울 거 같지만, 이를 하기 위해서는 많은 문제를 해결해야 한다.

위의 예시는 random noise를 input으로 두고 특정 뉴런을 활성화 시키기 위해서 input을 변화시켜나가는 과정으로 보인다.
Optimization Objective

- Neuron: $layer_n [x,y,z]$
- Channel: $layer_n[:, :, z]$
- Layer: $layer_n[:,:,:]$
- Class Logit:pre_softmax[k]
- Class Probability: softmax[k]
주목할 점은 특정 class의 softmax 값을 증가시키는 쉬운 방법은 해당 class에 가깝게 만드는 것이 아니라, 다른 class과 유사하지 않게 만드는 식으로 optimization이 진행된다는 것이다. 경험상 class logit을 objective로 삼는 것이 더 좋은 결과를 얻을 수 있었다.
위의 방법론 말고도 여러가지 방법을 시도해 볼 수 있다. style transfer도 좋은 예시이다. style transfer에서는 content와 style이라는 개념이 나온다. model이 optimization을 진행할 때 어떤 정보는 유지하고 어떤 정보는 버리는지에 대해서 알 수 있다.
Why visualize by optimization?
왜 dataset 그 자체로는 feature visualization을 하지 않고 optimization을 사용하는가?
이는 optimization이 model이 실제로 보고 있는 것을 시각화 할 수 있는 효과적인 방법이기 때문이다. 실제 dataset은 neuron이 보고 있는 것과 차이가 생길 수 있다.
그 이유는 optimization이 model의 행동을 유발하는 요소와 상관관계가 있는 요소를 분리할 수 있기 때문이다. 아래의 예시 이미지를 보면 쉽게 알 수 있다.

또한 optimization은 유연하다는 장점을 가진다. 특정 neuron을 활성화 시키고 싶다면 그에 맞게 수식을 적용하면 된다.
Diversity
optimization을 사용할 때는 주의할 필요가 있다.예를 들어, genuine을 표현하고 싶은데, facet의 특징으로 설명할 수 도 있다.
여기서 Dataset example이 매우 큰 장점을 가진다. 이를 통해서 diverse example을 찾을 수 있었다.
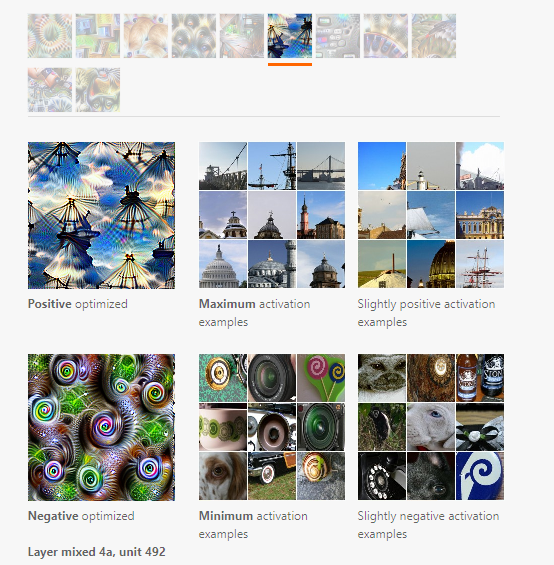
Achieving Diversity with Optimization
nework는 inputs의 넓은 범위에 활성화될 수 있다. 예를 들어서 class level에서 생각해보자. 만약 classifier가 개를 인식하게 학습이 되었다면, 해당 classifier는 개의 얼굴과 전체적인 시각적인 특징을 잡아내야 한다. (비록 시각적으로 그 둘의 차이가 크더라도)
- related work
이전의 연구에서 intra-class diversity에 대해서 밝히려는 시도가 있었다. [1]
training set에서 나오는 모든 activation을 수집해서 clustering을 하였다.
다른 방식으로 접근한 예도 있다. [2] 이 방법은 optimization process의 staring point를 가지고 intra class diversity를 증명하려고 했다.
최근의 연구로는 generative model과 결합한 시도가 있다[3]
이 글에서 제시하는 방법은 간단하게 적용할 수 있다. diversity term을 objective에 추가해서 multiple example이 서로 다르다고 하게끔 학습이 진행된다. 결과가 개선되었는데 정확한 이유는 아직 알 수 없다. 다만 추측하기로는 penalize the cosine similarity 혹은 feature가 다른 style로 보일 수 있게끔 학습이 진행되어서 그런것이라고 보고 있다.(style transfer)

오른쪽을 보면 다양한 뷰의 강아진 사진이있다. 그리고 왼쪽의 결과물은 diversity를 고려한 optimization의 결과물이다.

위의 그림은 diversity를 고려하지 않은 결과물이다.
Interaction between Neurons
neuron은 혼자서 작용하는 것이 아니라 다른 neuron과의 상호작용을 통해서 결과물을 도출한다. 이를 이해하기 위해서 geometrically하게 생각하는 것을 추천한다.
activation space를 activation의 모든 조합이 나올 수 있는 공간이라고 정의하자. 그렇다면 우리는 activation자체를 basis로 생각할 수 있다. 그리고 activation의 조합은 activation space에서 vector의 역할을 한다.
위에서 언급한 activaiton space, combination of activation, vector는 basis vector가 다른 vector에 비해서 더 해석하기 쉬울까에 대해서 논의할 수 있다.
이전의 연구에서 basis vector의 direction이 더 쉽게 이해할 수 있다고 한다. [1] [2]
그리고 이글에서의 실험도 위의 견해와 일치하게 결과가 나왔다.

위의 이미지는 각 이미지에 대한 optimization을 적용하였을 때의 결과물이다.

위의 결과물도 흥미롭다. direction을 정의할 수 있다는 것인데, mosaic neuron에 흑백의 neruon을 더하면 흑백의 mosaic neuron이 나오게 된다. 이는 word2vector 혹은 generative model의 latent space와 유사한 개념이다.
(interpolation)
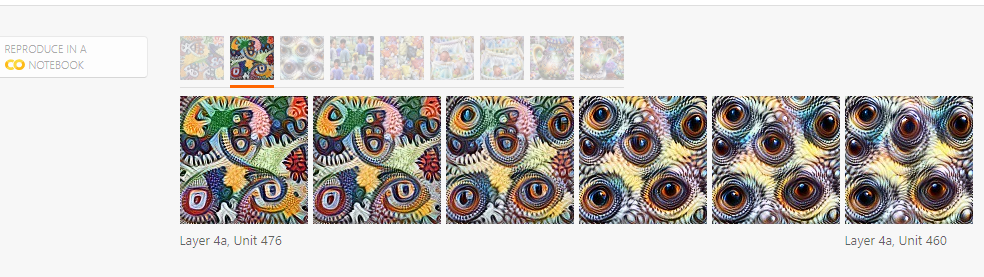
위의 이미지는 두 뉴런의 interpolation의 결과물이다. 해당 뉴런이 어떤식으로 결합되는지 확인할 수 있다. 위의 방법으로는 아주 작은 힌트만 얻을 수 있다. 예를 들면, 몇개의 interaction이 존재하는지 하지만 실제상황에서는 수백개의 interaction이 존재한다.
The Enemy of Feature Visualization
위에서 말한 optimization 방법론은 실제로 잘 작동하지 않는다. 아래 이미지와 같은 약간 이상하면서 자주 나타나는 패턴이 있다. 이 이미지는 실제 data상에서 잘 보이지 않는 패턴이며, 특정 뉴런을 활성화 시키기 위한 cheeting 같은 느낌이 든다. 이는 adversarial attack과 유사해보인다
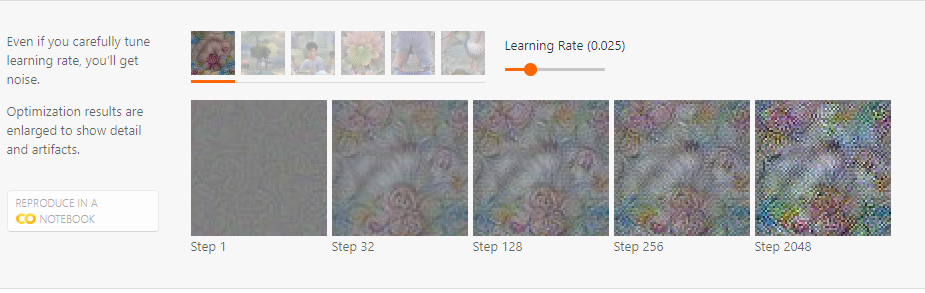
위에서 언급한 자주 보이는 패턴이 convolution과 pooling 연산에 의존적임을 확인할 수 있었다.

정리하자면, constraint없는 optimization은 매력적이긴 하지만, 위의 예시처럼 의미없는 결과를 불러올 수 있다. (결국 adversarial example과 유사하게 만들어진다.)
The Spectrum of Regularization
위의 자주 보이는 패턴을 다루는 것은 feature visualization 연구에서 매우 중요한 영역이다. 만약 더 유용한 visualization을 원한다면, prior, regularizer, constraint를 조합하여 만들어야한다.
연구분야에서는 regularization에 대한 관심이 많아보인다.
Reference
https://distill.pub/2017/feature-visualization/