Efficient Architecture 정리글
Efficient Architecture
딥러닝 모델을 경량화하는 방법 중에서 효율적인 구조를 채택하는 방법이 있다. 이를 efficient architecture라고 하겠다.
효율적인 구조라고 함은, 네트워크의 성능은 유지하면서 속도를 빠르게 하거 크기를 줄이는 것이다. 이번 글에서는 efficient architecture에 대해서 전반적인 흐름을 살펴볼 계획이다.
MobileNet-V1: Depthwise-separable convolution
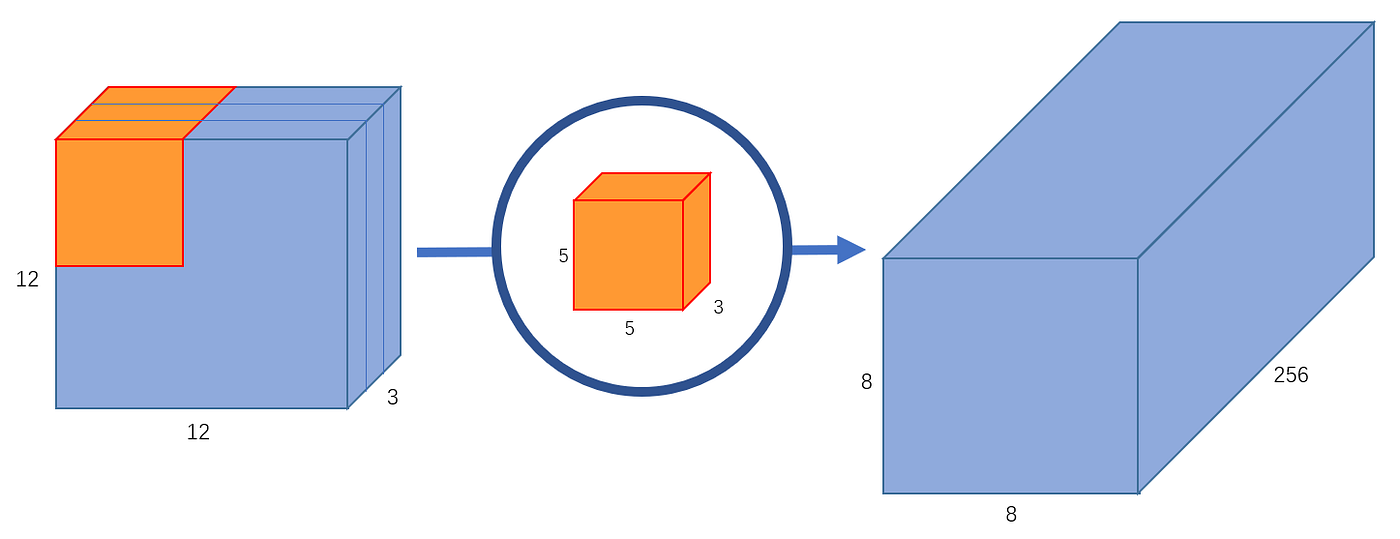
Convolution layer는 다양한 영역에서 좋은 성능을 보여주며, 많은 영역에서 활용된다. 아래의 convolution 연산량에 대해서 생각해보자.

위의 연산은 다음과 같은 연산량을 가진다.
만약 output의 channel의 수가 256이길 바라면, $5 \times 5 \times 3$이 256개 있으면 된다.
다시 연산량을 계산해보면, 아래와 같다.
위의 예시에서 살펴본 결과, convolution의 연산량은 원하는 output filter의 개수와 선형적으로 증가하며, 다른 변수(input dim, channel, kernel size)에 의해서도 모두 선형적으로 증가한다. 따라서, 각 요소들이 모두 선형적으로 늘어나게 되면, 연산량은 폭발적으로 늘어나게 된다.
Depthwise-separable convolution은 이름에서처럼 위의 연산을 두 단계로 나누어서 진행한다. 이는 spatial separable convolution과 유사한 직관을 가진다.

Depthwise-separable convolution은 크게 두 가지 파트로 나눈다.
- Depthwise convolution
- Pointwise convolution
Depthwise Convolution
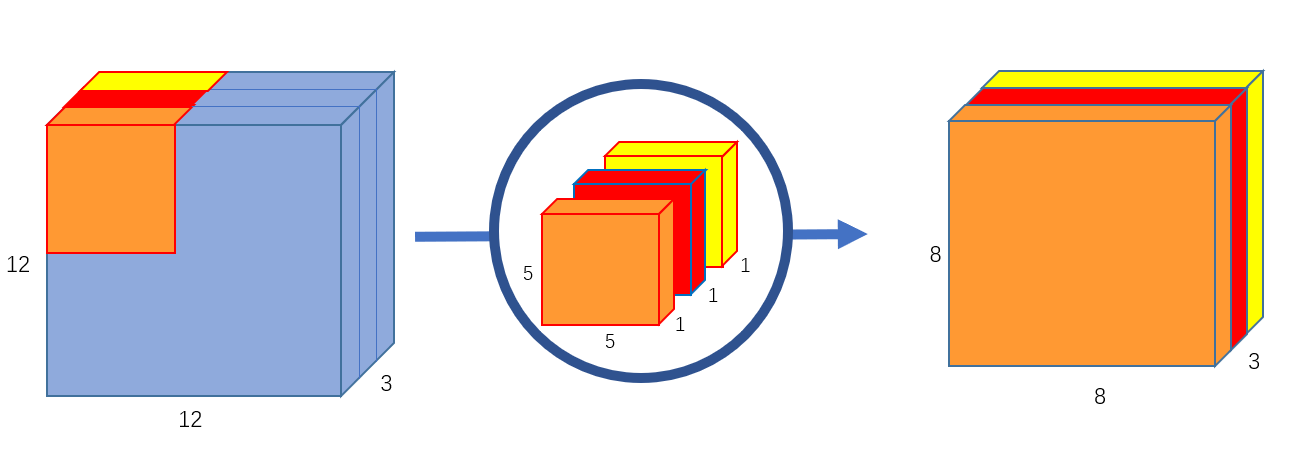
말그대로 depth 별로 filter를 두는 것이다. 위의 보이는 이미지처럼 한 filter가 하나의 차원을 담당한다. 그리고 output과 input의 depth는 같다.
Pointwise Convolution
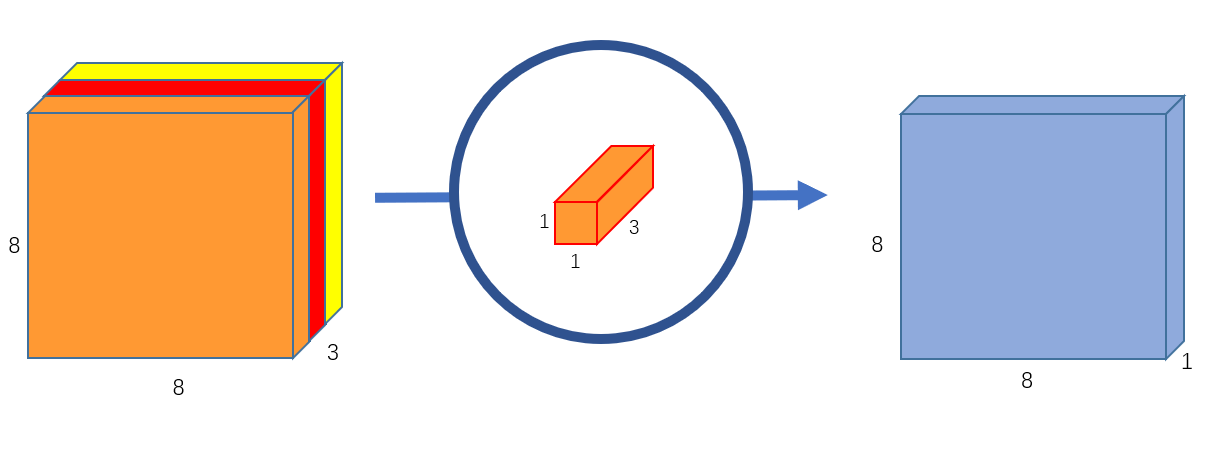
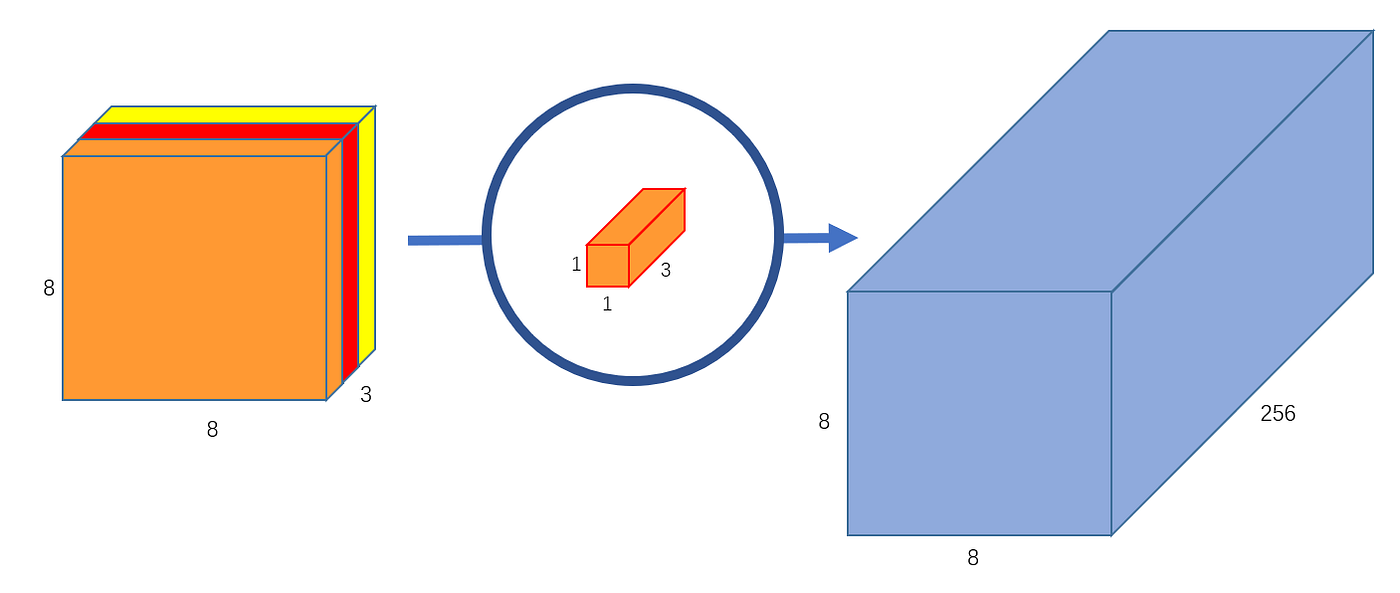
한 point의 모든 depth에 대한 정보를 가지고 있는 kernel이다. kernel의 개수를 늘리면, output의 depth가 늘어난다.
위의 두 연산을 합치면, depthwise convolution에서는 kernel size를 조절할 수 있으며, pointwise convolution에서는 depth를 조절할 수 있다. 따라서, 기존의 convolution과 유사한 역할을 할 수 있다.
depthwise-separable convolution의 연산량을 구해보면 아래와 같다.
Performance
Depthwise-separable convolution은 MovileNet V1에서 제안한 구조이다. 성능에 대한 것은 아래를 참고하면 된다. depthwise convolution을 적용한 것이 그렇지 않은 것보다 parameter 수는 약 5 ~6배 정도 작지만, 성능은 1%밖에 차이가 안난다.

### MobileNet-V2: Inverted Residual

위의 이미지는 output의 dimension이 작을수록 activation space에 입력채널의 정보를 전달하기 힘들다는 것을 보여준다. 따라서, activation을 작은 차원으로 mapping 시키는 것은 정보손실을 가져올 수 있다.

이러한 직관을 가지고 inverted residual block을 제안하는데, 기존의 residual block과 bottleneck 이후 channel을 확장하고 그 다음 layer는 차원은 유지하면서 비선형 변형의 역할을 수행한다.
조금 더 자세히 살펴보면, 위의 구조는 아래의 실험결과를 바탕으로 제안되었다.
- Convolution은 낮은 차원에서 잘 작동하지 않는다. -> 높은 차원에서 convolution을 진행해야한다.
- 낮은 차원으로의 비선형 변환은 정보손실을 많이 한다. -> 높은 차원으로 비선형 변환을 한다.
Memory Efficiency Inference
inference시 메모리를 효율적으로 활용가능하다. 이는 input과 output을 작게 유지할 수 있기 때문이다.
MobileNet-V3: Architecture Search

Mobilenet V3는 이전 방법론과 다르게, AutoML을 적용하여, architecture search를 진행하였습니다. 이전에는 효율적인 구조에 대해서 직접 설계했다면, V3는 objective만 명확히 설정하면, 자동으로 최적의 구조를 찾습니다.
위의 이미지는 그 과정을 나타냈습니다. Controller는 효율적인 architecture를 찾습니다. child network는 학습이 진행되며 학습된 결과를 바탕으로 controller에서 gradient를 전달합니다.
NAS: Neural Architecture Search
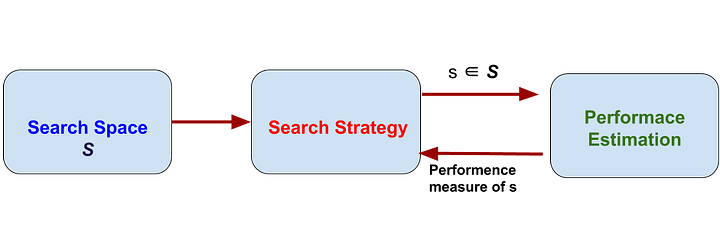
NAS는 위의 이미지처럼 크게 세 가지 영역으로 구성된다. NAS는 preformance를 최대화 하는 search strategy를 찾는다.
search space
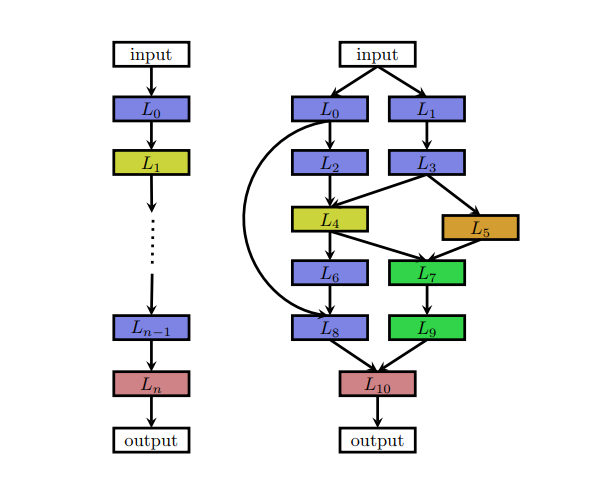
NAS가 찾을 neutal architecture를 결정한다. Chain-like architectuer이거나, skip connection을 포함한 복잡한 구조일 수도 있다.
Search strategy, Performance estimation
위의 주제를 다루기 위해서는 강화학습과 RNN을 언급하고 가야한다. controller가 performance를 최대화하는 방향으로 optimize된다. 이때, 사용되는 방법론이 강화학습이다. 그리고 controller는 RNN으로 구성되어 있다.
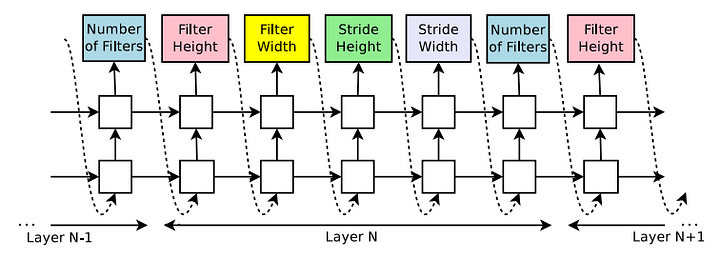
위의 이미지를 보면, filter의 개수부터 filter의 높이까지 다양한 영역의 hyperparameter를 RNN의 output으로 가진다. RNN의 output으로 architecture를 설계하고 학습 후 이를 reward를 반영한다.
여기서 RNN의 parameter는 강화학습에서 policy로의 역할을 하며, reward를 바탕으로 objective에 더 적합한 architecture를 만들어내도록 학습이 된다. 참고로, loss함수가 미분가능한 함수가 아니라서, iterative한 방법을 통해서 학습이 된다.
MixNet: Mixed Depthwise Convolutional Kernel
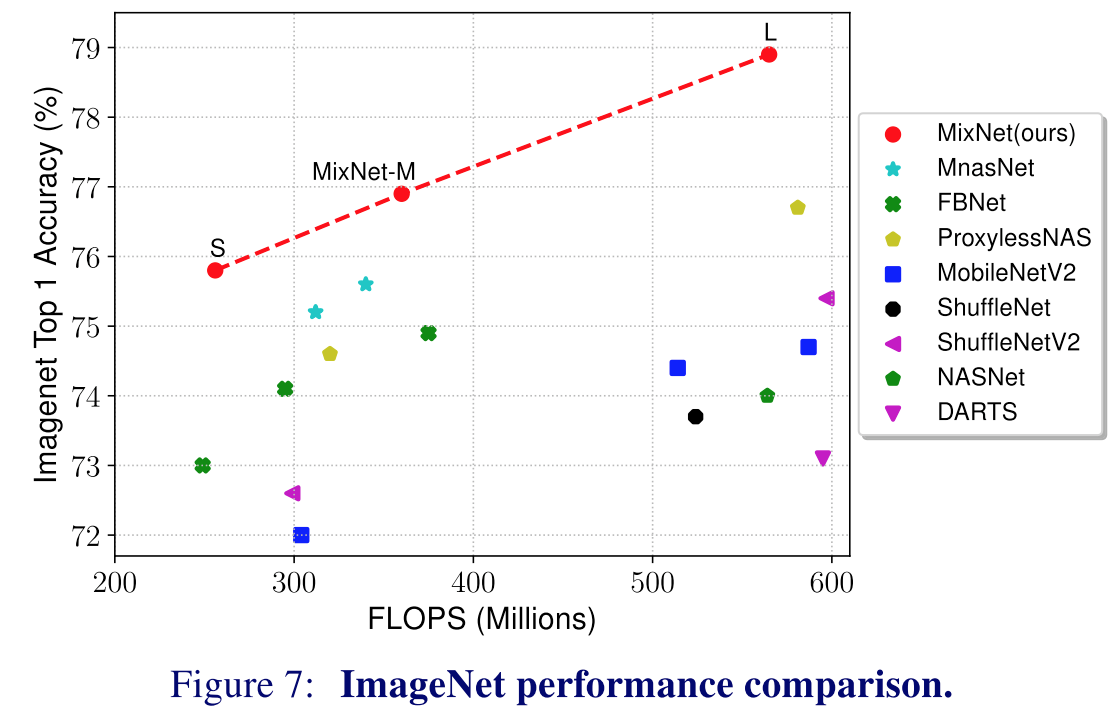
Depthwise convolution kernel을 AutoML 방법론으로 잘 섞어서 효율을 최대화 하는 방법입니다. 성능은 아래와 같습니다.
EfficientNet
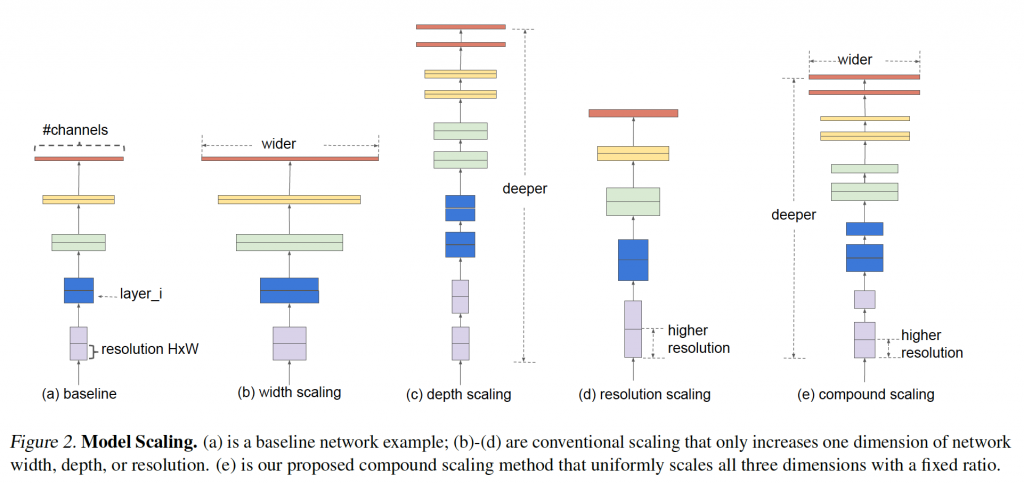
본 논문에서는 baseline cnn을 선택하여, 필터의 개수, 레이어의 개수, 입력 데이터의 해상도를 높이는 실험을 하여 아래처럼 성능을 확인하였다. 확인 결과, 일정수준이상이 되면 accuracy가 증가하는 폭이 낮아짐을 알 수 있었다. 따라서, 저자들은 이러한 세 가지 요소를 조화롭게 활용하며 최적의 모델을 만들고자 했다.
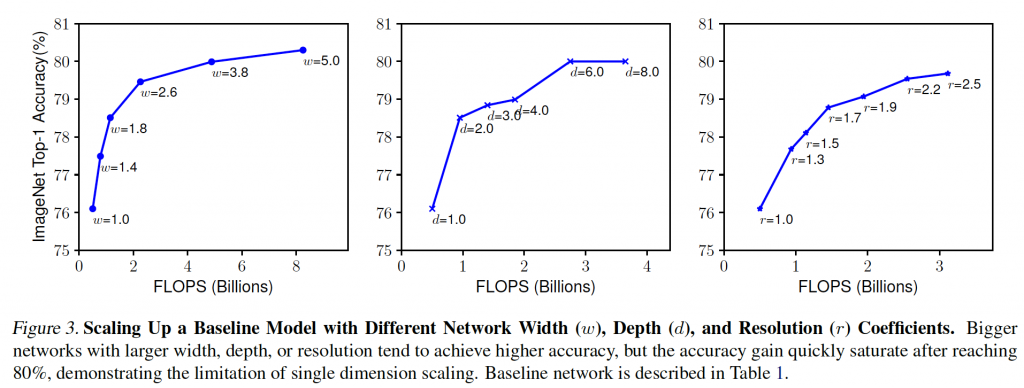
복합모델스케일링은 위의 세 가지의 factor를 조합하여, model을 만드는 것이다. 자세한 내용은 아래의 reference를 확인하기 바랍니다.
MNasNet
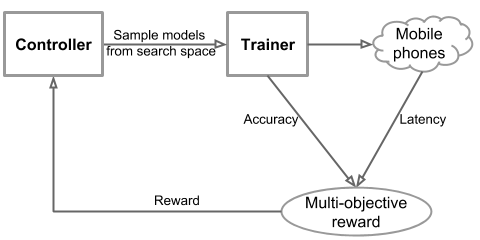
위에서 언급했던 NAS는 하나의 objective를 받았던 반면에, MNasNet은 multi objective reward를 활용하여 최적화된다.
Reference
[1] 경량화 이모저모
[2] depthwise-separable convolution
[4] MobileNet-V1
[5] MobileNet-V2
[6] MobileNet-V3
[7] Neural Architecture Search Blog
[9] MNasNet Blog